Hi all, I started to analyze my data from the outdoor unit and apply the correction algorithms to check against a reference device in my city (not co-located though) to see how these perform. I do not know if my PM sensor would be of a batch for which AirGradient is aware the correction wouldn’t work (and I do not know how that would look like either). But I’d like to share some initial thoughts / ideas here:
-
If the background for the correction is the electronics heating up the air, could we expect the effect to happen only on the temperature and not on the absolute humidity? In other words, if we assume the dew point to be correct, one could potentially derive the correct relative humidity based on the dew point after correcting the temperature (rather than having two separate correction algorithms for each of them). Have you tried to investigate this already?
-
Even though I have seen the plots showing R2 > 0.99 (link), I’m still not certain whether a linear regression should work as expected to correct the measured temperature. I’d rather think that this assumes the outside temperature to change at a somewhat steady pace, but is this the case? I think one may experience smoother or steeper changes in the outdoor temperature in different locations, which might then impact how the heated air inside the enclosure responds to it, does it make sense?
Below I share some further details to support the discussion on each of these points:
(1)
In my case, as I do not have co-located outdoor monitor and reference (they are ~30 km apart from each other), I cannot fully verify this idea, and I rather observe an offset between the actual dew point and the one estimated based on the AG measures (temperature and RH):
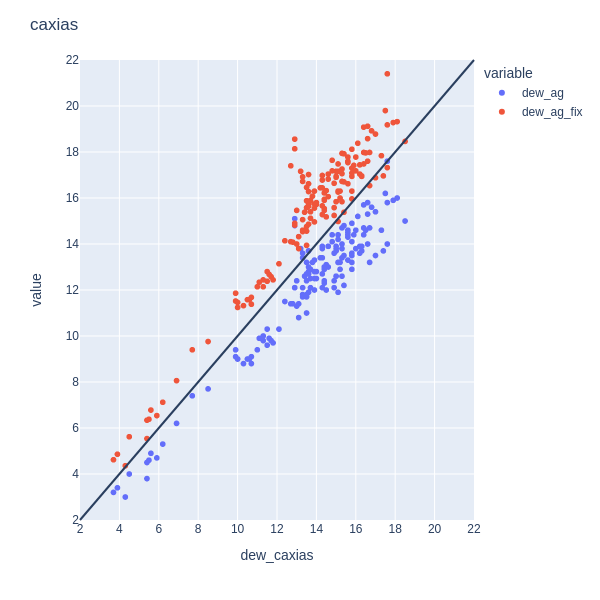
The x-axis is the reference device’s dew point, and the y-axis is from the AG monitor. Blue points are raw values, and red points are those after applying correction for both temperature and RH. We see the pattern doesn’t change that much in respect to the diagonal line (black line).
Here are some stats comparing these values:
raw AG → RMSE = 1.7 ; slope = 1.02 ; intercept = 1.2 ; R2 = 0.91
corrected AG → RMSE = 1.8 ; slope = 0.89 ; intercept = 0.2 ; R2 = 0.92
So I still found quite interesting to observe that the slope for the raw AG measures in respect to the reference is close to 1, and also that the RMSE of the raw dew point is even lower than the one after correction.
(2)
Here’s a hypothetical example to illustrate the idea:
Day X: outside temperature starts at 30°C and then drops to 10°C in four hours
Day Y: outside temperature starts at 15°C and then drops to 10°C in four hours
Why would one expect that the sensor temperature readings in both days X and Y would be the same in the end (when outside temperature 10°C)? I think there will be a considerable difference between those readings due to the initial temperature the monitor was exposed to. If that’s the case, then the linear regression would yield different values - and likely on day X, it would present a greater deviation.
In other words, I think the corrected temperature should not only depend on the instant temperature as measured by the sensor, but also on some estimation of the outside air temperature variation (if at all possible - but maybe observing the ratio of the temperature change in the sensor itself could help).
Below is an example I have observed with the data I collected: we see two consecutive days and how the actual temperature dropped differently at night, even though it started more or less at the same level:
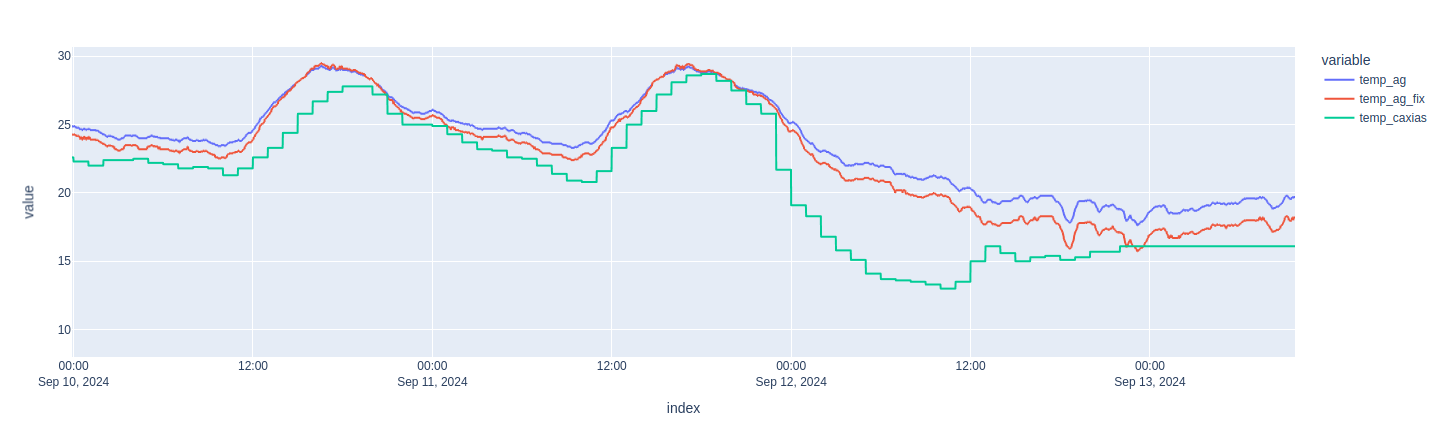
One may observe that, in the second drop (Sept 12th), the green line (actual outside temperature) has a steeper decrease, and both AG estimations (blue = raw ; red = corrected) are no longer able to keep the same pace (as opposed to what happened in the first drop on Sept 11th).
Again, I’m not sure if this is all true, as my monitor is quite far from the reference device, but at least on my mind the reasoning seems to make sense.
Looking forward to hearing other perspectives around these points, and hopefully learn more about it. I’ll keep collecting more data to have more robust analysis. (BTW, I was also wondering if we could also have access to the data used in the past to create the correction algorithms, that could be very insightful).